I’m developing a MicroPython-based product running on an NXP i.MX RT1176 (Cortex-M7 @ 1 GHz) with a 720x1280 MIPI DSI touchscreen driven by LVGL v9. It’s an embedded system, not a phone or PC. The on-screen keyboard was unusable. Each keypress took nearly 200ms to render, dropping to 1-2 FPS while typing, missing many keypresses entirely. This same LVGL keyboard widget is routinely used on much slower microcontrollers. Something was fundamentally wrong with how our system was configured, but the rendering stack is deep and the root cause wasn’t obvious.
This was a potential project-stopper. The conventional path, a senior embedded engineer spending weeks with a debugger and profiler methodically working through the rendering pipeline, would have taken 3-4 weeks of dedicated work. Worse, early results might have suggested the hardware wasn’t capable, triggering a redesign discussion that delays the project by months.
Instead I set up an agentic investigation with Claude Code and went back to my other work.
This is a case study in methodology, not magic. The approach is transferable to any performance investigation where you can define a measurable metric and iterate autonomously.
The Methodology
The approach that emerged rests on three principles I think are broadly applicable to any autonomous AI debugging workflow.
1. Define an Autonomous Eval
Before touching any code, I needed a metric that Claude Code agents could measure independently, without me watching. The 20-key keyboard benchmark became this: select each of 20 buttons in sequence, measure lv.timer_handler() execution time for each via time.ticks_us(), report average/min/max.
Same principle behind evals in ML. If you can’t measure it automatically, you can’t iterate on it autonomously. The benchmark script runs on the device via mpremote, takes ~5 seconds, and produces a single number (average ms per frame). An agent can build firmware, flash it, run the benchmark, and report whether a change helped, all without human intervention.
2. Keep a Persistent Investigation Log
Claude Code sessions have context limits. Long sessions get compacted. Sub-agents can’t see the main session’s history. The investigation log (INVESTIGATION_LOG.md) is the shared memory that survives all of this, a chronological record of what was tested, what was measured, and what was concluded.
Every agent writes its findings to this log. When a new session starts (or context compresses), the log provides continuity. This turned out to be pretty critical: the investigation spanned 21+ sessions across 10 days. Without the log, each session would have started from scratch.
3. Delegate to Preserve Context
Every sub-task that involves deep code reading, building, or testing goes to a sub-agent. The main session stays lean, making decisions, steering direction, recording results. This isn’t just about parallelism (though that helps). It’s about keeping the orchestrator’s context window focused on investigation strategy rather than filled with build output and source code.
The Brainstorm
I described the problem to Claude Code and launched a team brainstorm: four parallel agents (hardware-focused, software-focused, a critic, and a side investigation into GPIO interrupt support) collaborating through a shared channel.
Within an hour, with zero further input from me, they identified the compound effect chain that explained the symptoms:
Software rotation (1.7MB column-major copy every frame) was causing SDRAM row thrashing, which evicted the entire 32KB D-cache, which made garbage collection run with cold cache, which made “GC is surprisingly slow” actually a symptom of “rotation pollutes the cache.” The agents cross-pollinated this between hardware and software perspectives. Neither would have found it alone.
They produced a ranked test plan with four execution phases, ordered by information value per unit of effort. I reviewed it in about 10 minutes and approved.
The Overnight Shift

I left Claude running in a tmux session with the hardware connected and went to work on other projects. Seven agents ran in parallel for 21+ hours, building firmware, flashing, running benchmarks on the actual device:
- A linker planning agent identified that our 64MB GC heap was scanning framebuffer memory during garbage collection (107ms per collection), and planned a fix to move framebuffers into dedicated linker sections
- A styling agent measured the cost of per-button border rendering (10ms overhead across 40 buttons) and tested flat-fill alternatives
- An SWO trace agent spent 4+ hours setting up on-chip debug trace, confirming that DWT PC sampling doesn’t work on this silicon revision, a dead end but a valid experimental result that produced a working ITM printf path used later
- A touch driver agent implemented interrupt-driven input to replace polling
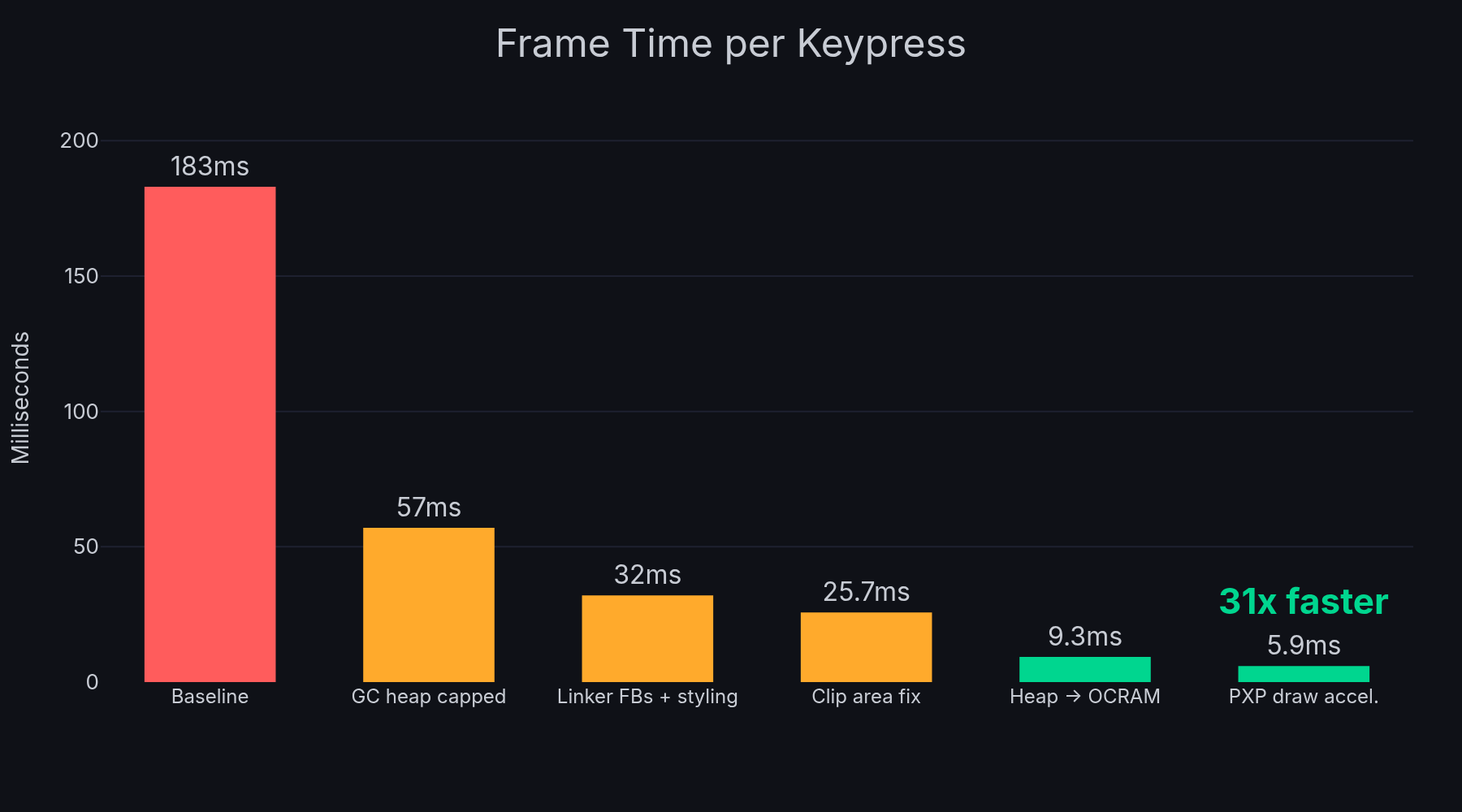
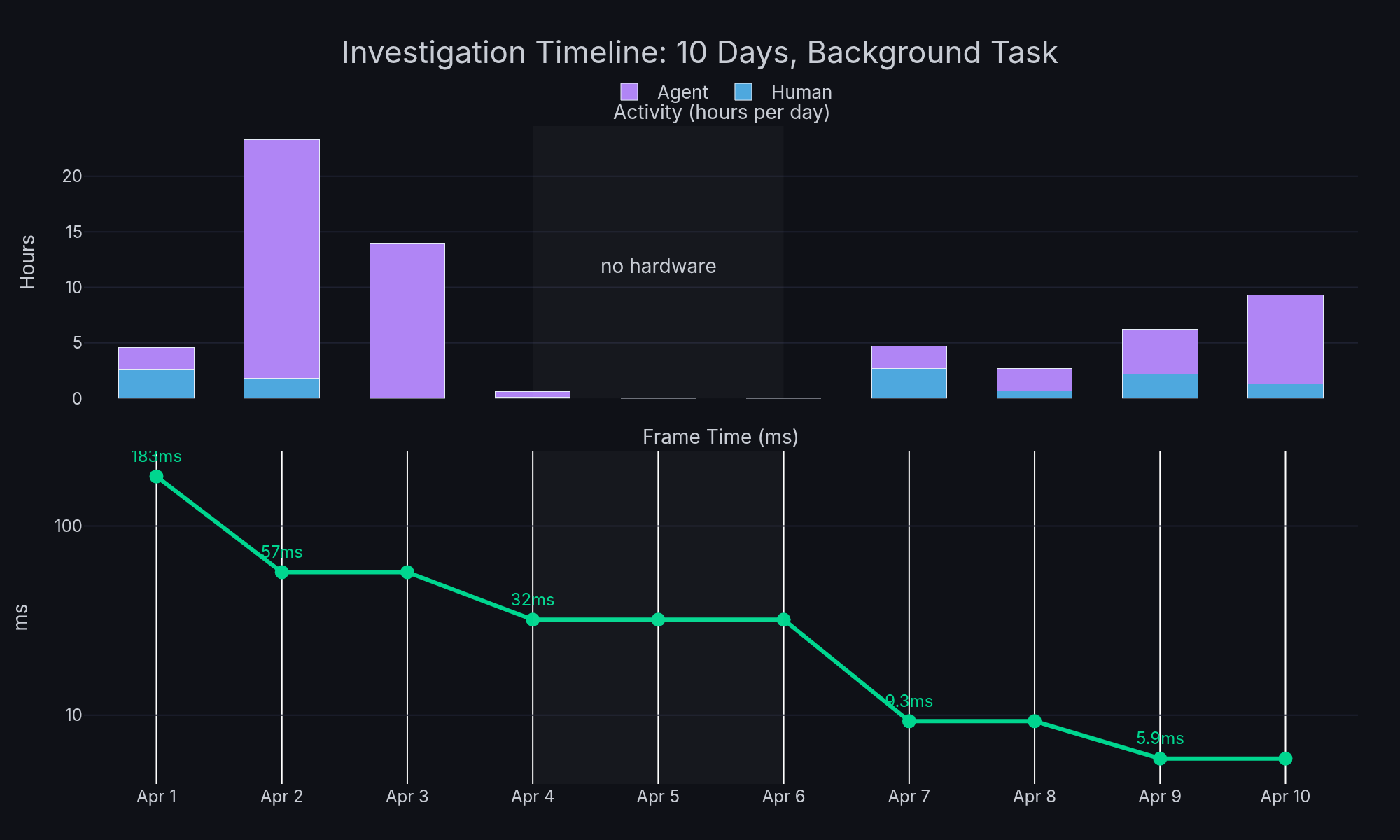
When I checked in the next morning, the build-flash-test agent had already compiled a firmware with the accumulated fixes and benchmarked it: 57ms average, down from 183ms. The gc.collect() time dropped from 107ms to 61 microseconds, a 1,750x improvement from simply capping the heap size and moving framebuffers out of GC-managed memory.
I didn’t write any of that code. I didn’t run any of those tests.
Hitting a Plateau
The autonomous work brought us from 183ms to about 32ms over the next couple of days. Good progress, but typing still felt sluggish. I was doing a couple of things at this point.
First, I prompted a separate agent to compare our hardware configuration against the Phytec-provided Zephyr profile for the same system-on-module, looking for differences in clock speeds, bus timing, SDRAM configuration, MIPI settings. It came back pretty clean, the configs were broadly similar. No smoking gun there, but it ruled out a whole class of potential issues.
Second, I called out that the trial-and-error styling approach wasn’t productive: “this trial and error approach isn’t working, need a real benchmark up and down the stack.” This forced the shift to systematic instrumentation. Claude added DWT cycle counter profiling inside LVGL’s render loop, and the results were clear: style resolution (LVGL walking the widget property tree to resolve colours, borders, fonts for each button) consumed 95-97% of render time.
The Clip Area Fix
This led directly to a fix in LVGL’s buttonmatrix widget. The draw_main() function was iterating all 40 buttons on every frame, doing full style resolution on each one, regardless of which part of the screen was actually dirty. Adding a clip area check to skip off-screen buttons before the expensive style resolution loop was a four-line change. 4x improvement. Submitted upstream as lvgl/lvgl#9946.
That brought us to about 25ms. Better, but still not where it should be.
The Key Human Insight
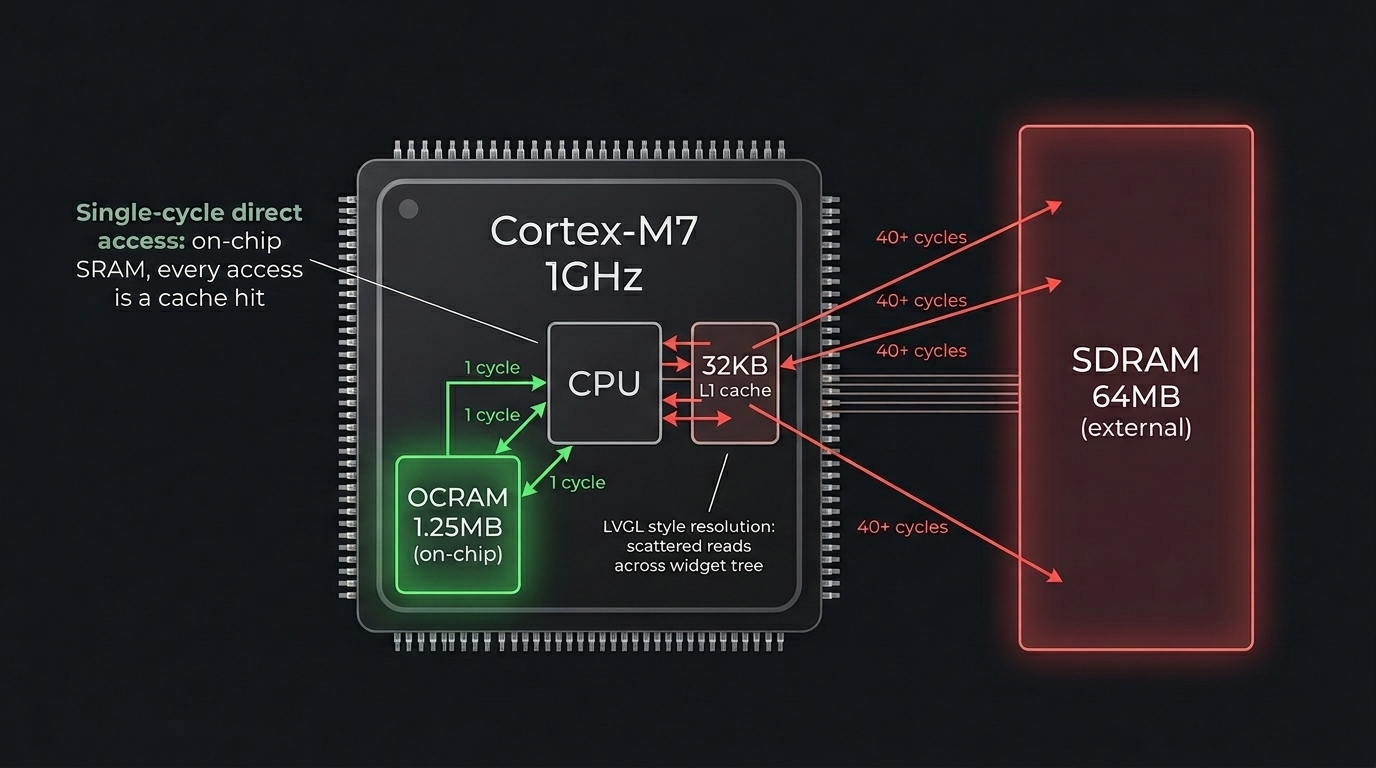
The profiling showed that style resolution was the bottleneck, but the agents had been focused on reducing the amount of work (skip off-screen buttons, simplify styles). The question I kept coming back to was: why is this slow at all? LVGL keyboards work fine on much slower MCUs.
The difference is memory. Those slower MCUs all use on-chip SRAM for everything. Our RT1176 has 64MB of external SDRAM, and that’s where the MicroPython GC heap lived, which is where LVGL allocates all its widget objects and style data. The scattered read pattern of LVGL’s style property walks was hitting SDRAM cache miss latency on every access, probably around 40 cycles per miss compared to single-cycle access for on-chip memory.
I asked Claude to test moving the GC heap from SDRAM to the chip’s on-chip OCRAM (1.25MB, much smaller but much faster). Frame time dropped from 25.7ms to 9.3ms. A 3x speedup from changing two lines in the linker script.
The agents had spent hours profiling the render pipeline. The fix was a memory placement decision that came from embedded systems intuition about cache behaviour. This is the collaboration model: AI is thorough and tireless at instrumentation and measurement; the human provides the architectural intuition that reframes the problem.
Colleague Replication
Once the initial results looked good, a colleague tried to replicate the build on their hardware. This is a step I’d recommend for any investigation, it catches assumptions you’ve baked in without realising.
They hit two issues. First, LV_DRAW_BUF_ALIGN was set to 4 in the committed config but I’d been building with 32 locally (needed for PXP and cache line alignment). The build failed for them. Second, even after fixing that, they measured 174ms, basically back to square one.
This led to investigating what was different about their build. It turned out PXP (NXP’s Pixel Processing Pipeline) draw acceleration was completely disabled in our config, LV_USE_PXP=0. The earlier Zephyr comparison had noted PXP existed in the Zephyr config but at the time it wasn’t clear it mattered for draw operations (we’d been thinking of PXP mainly for rotation). Enabling it offloads rectangle fills and blits from CPU to hardware.
The Final Push
With PXP draw enabled: 5.9ms average. 169 FPS. 31x improvement from baseline.
Then we went further. Runtime display rotation from Python (so the application chooses portrait or landscape at init time, not a compile-time rebuild). Centralised build configuration across the display driver, LVGL binding, and board config (3-phase spec/plan/execute cycle with independent review agents at each step). Widget demos in both orientations. The upstream LVGL PR with AI-assisted code review. The autonomous execution pipeline handled the implementation while I provided direction.
The Numbers
| Metric | Value |
|---|---|
| Starting performance | 183ms / 1-2 FPS |
| Final performance | 5.9ms / 169 FPS |
| Improvement | 31x |
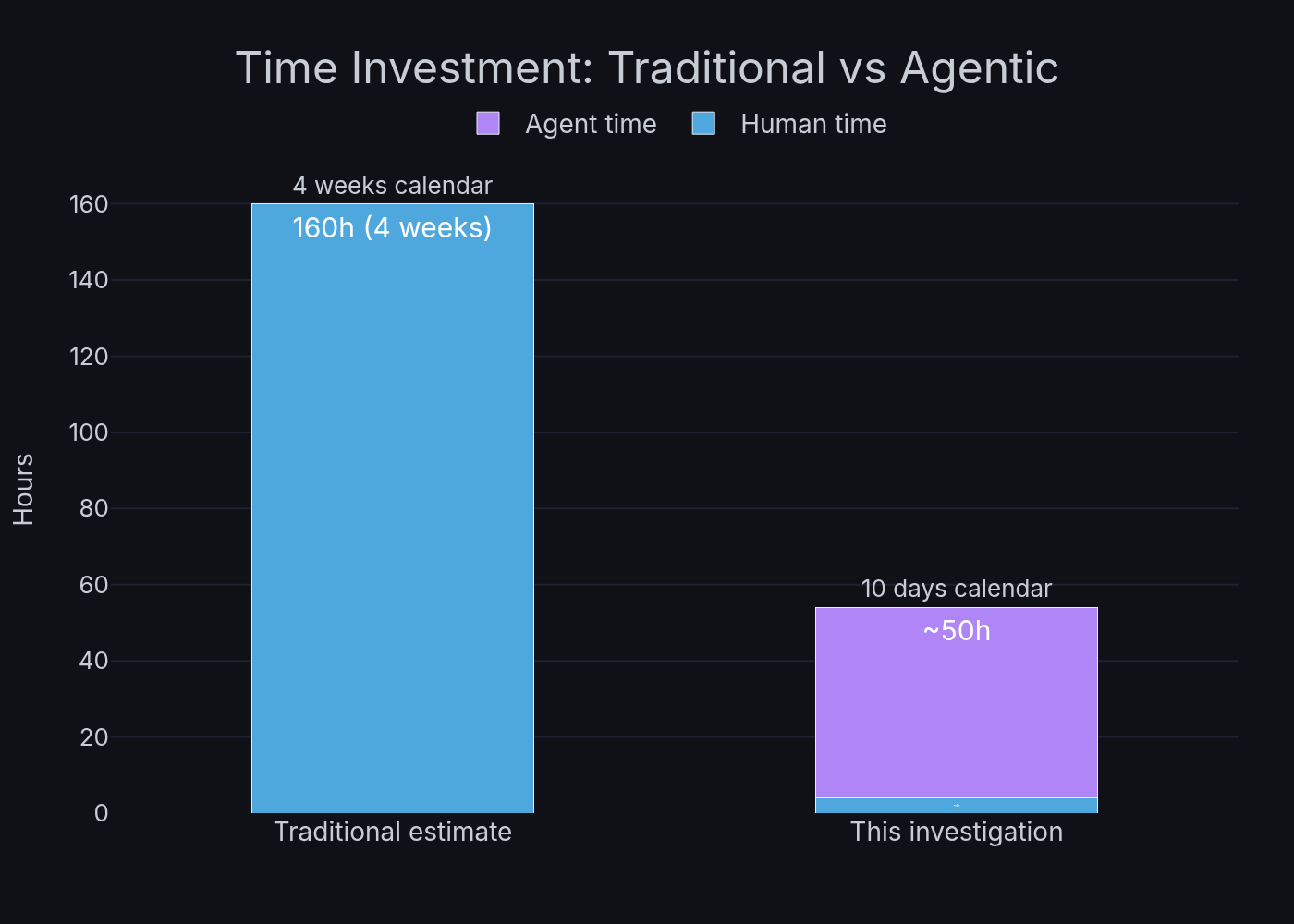
| Calendar time | 10 days |
| My active attention | ~3-5 hours total |
| Autonomous agent work | ~50 hours |
| Root causes found | 5 |
| Upstream contributions | 1 LVGL PR |
| Commits | 29 across 4 repositories |
During this investigation I was actively working on 4-5 other projects. The performance work was a background task, periodic check-ins to review autonomous results, provide hardware access, and make directional decisions. Claude’s session limits got hit a few times and we had to restart with fresh context, but the investigation log kept continuity.
Five Root Causes
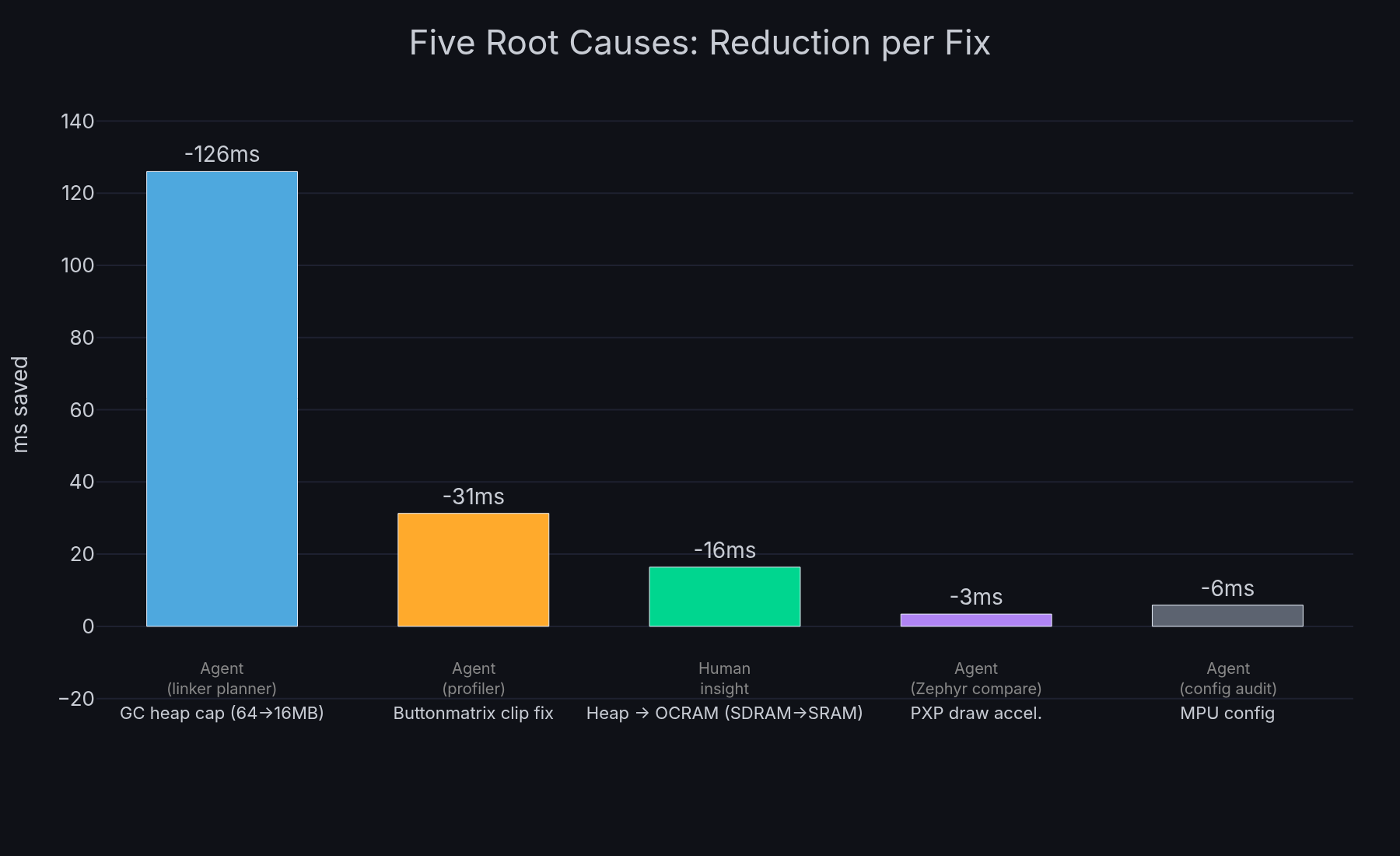
No single fix solved the problem. Each was necessary, and the investigation uncovered them roughly in this order:
- GC heap scanning 64MB of SDRAM including framebuffers, capping to 16MB and moving framebuffers to linker sections dropped gc.collect() from 107ms to 61us
- MPU not configured for cacheable SDRAM access, 31% improvement on memory operations
- LVGL buttonmatrix rendering all 40 buttons every frame regardless of which area was dirty, clip area check gives 4x
- GC heap in SDRAM (external memory with cache miss latency), moving to on-chip OCRAM gives 3x on the style resolution hot path
- PXP draw acceleration disabled, enabling hardware rectangle fills gives 1.6x
What Didn’t Work
Honest accounting matters for methodology.
SWO DWT PC sampling consumed ~6 hours of agent time across two days. The conclusion: it doesn’t work on this silicon revision. Valid result, but checking the errata sheet first would have saved the time. The investigation did produce a working ITM printf path that was used for later C-level profiling though.
Trial-and-error styling changes. I explicitly called this out as unproductive early on: “this trial and error approach isn’t working, need a real benchmark up and down the stack.” This forced the shift to systematic DWT instrumentation, which is what actually identified style resolution as the bottleneck.
SNVS register access for battery-backed storage caused hard faults. We didn’t have the access control sequence right. Deferred, and the failed attempt led to identifying an upstream MicroPython feature request that would solve it properly.
Transferable Methodology

Strip away the embedded specifics and the approach is:
Start with a brainstorm, not code. Launch parallel agents with different perspectives on the problem. The compound root cause in this investigation only emerged from cross-pollination between hardware and software viewpoints.
Define your eval before optimising. A metric that agents can measure autonomously is the foundation. Without it every change requires a human to evaluate, and you’ve lost the ability to iterate in the background.
Log everything persistently. The investigation log is the shared memory across sessions, agents, and context window resets. It’s cheap to maintain and pretty much invaluable for continuity.
Delegate execution, keep strategy. Sub-agents do the building, testing, code reading, and profiling. The main session stays focused on “what should we try next” rather than “how do we implement it.”
Let agents run overnight. 21+ hours of parallel investigation happened while I was working on other things. The ROI of this approach compounds when you treat AI agents as a team that works while you sleep.
Human intuition still matters. The biggest single improvement (3x from OCRAM) came from a human observation about slower MCUs. The agents measured everything precisely but didn’t make the lateral connection. This is the collaboration, AI thoroughness multiplied by human intuition.
Have someone else replicate your results. The colleague’s failed build exposed a config assumption I’d missed, and the investigation into their poor performance led directly to the final PXP unlock.
Contribute upstream. The LVGL clip area fix benefits everyone using LVGL buttonmatrix widgets. Agentic investigation can produce upstream-quality contributions, not just local patches.
The investigation used Claude Code (Anthropic’s CLI) with Opus for orchestration and sub-agents. The target was an NXP i.MX RT1170 running MicroPython with LVGL v9 on a 720x1280 MIPI DSI display. All code changes, benchmarks, and the upstream LVGL PR are real and in production.